前情提要
点击链接查看“跳表”详细介绍。
简介
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
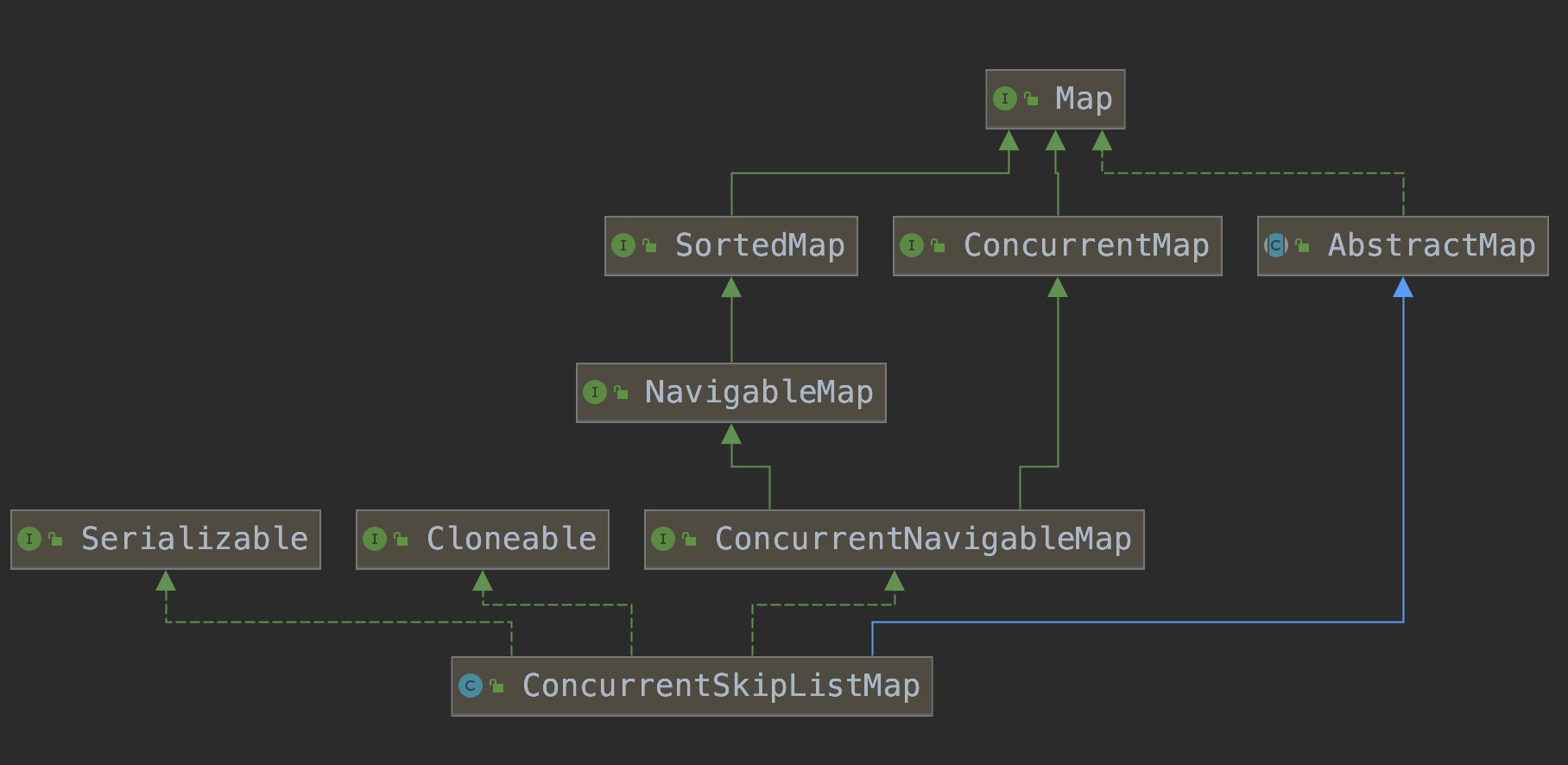
UML继承关系
存储结构
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。

源码分析
主要内部类
内部类跟存储结构结合着来看,大概能预测到代码的组织方式。
1 | // 数据节点,典型的单链表结构 |
(1)Node,数据节点,存储数据的节点,典型的单链表结构;
(2)Index,索引节点,存储着对应的node值,及向下和向右的索引指针;
(3)HeadIndex,头索引节点,继承自Index,并扩展一个level字段,用于记录索引的层级;
构造方法
1 |
|
四个构造方法里面都调用了initialize()这个方法,那么,这个方法里面有什么呢?
1 | private static final Object BASE_HEADER = new Object(); |
可以看到,这里初始化了一些属性,并创建了一个头索引节点,里面存储着一个数据节点,这个数据节点的值是空对象,且它的层级是1。
所以,初始化的时候,跳表中只有一个头索引节点,层级是1,数据节点是一个空对象,down和right都是null。

通过内部类的结构我们知道,一个头索引指针包含node, down, right三个指针,为了便于理解,我们把指向node的指针用虚线表示,其它两个用实线表示,也就是虚线不是表明方向的。
添加元素
通过【拜托,面试别再问我跳表了!】中的分析,我们知道跳表插入元素的时候会通过抛硬币的方式决定出它需要的层级,然后找到各层链中它所在的位置,最后通过单链表插入的方式把节点及索引插入进去来实现的。
那么,ConcurrentSkipList中是这么做的吗?让我们一起来探个究竟:
1 | public V put(K key, V value) { |
我们这里把整个插入过程分成三个部分:
Part I:找到目标节点的位置并插入
(1)这里的目标节点是数据节点,也就是最底层的那条链;
(2)寻找目标节点之前最近的一个索引对应的数据节点(数据节点都是在最底层的链表上);
(3)从这个数据节点开始往后遍历,直到找到目标节点应该插入的位置;
(4)如果这个位置有元素,就更新其值(onlyIfAbsent=false);
(5)如果这个位置没有元素,就把目标节点插入;
(6)至此,目标节点已经插入到最底层的数据节点链表中了;
Part II:随机决定是否需要建立索引及其层次,如果需要则建立自上而下的索引
(1)取个随机数rnd,计算(rnd & 0x80000001);
(2)如果不等于0,结束插入过程,也就是不需要创建索引,返回;
(3)如果等于0,才进入创建索引的过程(只要正偶数才会等于0);
(4)计算while (((rnd >>>= 1) & 1) != 0),决定层级数,level从1开始;
(5)如果算出来的层级不高于现有最高层级,则直接建立一条竖直的索引链表(只有down有值),并结束Part II;
(6)如果算出来的层级高于现有最高层级,则新的层级只能比现有最高层级多1;
(7)同样建立一条竖直的索引链表(只有down有值);
(8)将头索引也向上增加到相应的高度,结束Part II;
(9)也就是说,如果层级不超过现有高度,只建立一条索引链,否则还要额外增加头索引链的高度(脑补一下,后面举例说明);
Part III:将新建的索引节点(包含头索引节点)与其它索引节点通过右指针连接在一起(补上right指针)
(1)从最高层级的头索引节点开始,向右遍历,找到目标索引节点的位置;
(2)如果当前层有目标索引,则把目标索引插入到这个位置,并把目标索引前一个索引向下移一个层级;
(3)如果当前层没有目标索引,则把目标索引位置前一个索引向下移一个层级;
(4)同样地,再向右遍历,寻找新的层级中目标索引的位置,回到第(2)步;
(5)依次循环找到所有层级目标索引的位置并把它们插入到横向的索引链表中;
总结起来,一共就是三大步:
(1)插入目标节点到数据节点链表中;
(2)建立竖直的down链表;
(3)建立横向的right链表;
添加元素举例
假设初始链表是这样:

假如,我们现在要插入一个元素9。
(1)寻找目标节点之前最近的一个索引对应的数据节点,在这里也就是找到了5这个数据节点;
(2)从5开始向后遍历,找到目标节点的位置,也就是在8和12之间;
(3)插入9这个元素,Part I 结束;

然后,计算其索引层级,假如是3,也就是level=3。
(1)建立竖直的down索引链表;
(2)超过了现有高度2,还要再增加head索引链的高度;
(3)至此,Part II 结束;

最后,把right指针补齐。
(1)从第3层的head往右找当前层级目标索引的位置;
(2)找到就把目标索引和它前面索引的right指针连上,这里前一个正好是head;
(3)然后前一个索引向下移,这里就是head下移;
(4)再往右找目标索引的位置;
(5)找到了就把right指针连上,这里前一个是3的索引;
(6)然后3的索引下移;
(7)再往右找目标索引的位置;
(8)找到了就把right指针连上,这里前一个是5的索引;
(9)然后5下移,到底了,Part III 结束,整个插入过程结束;

是不是很简单^^
删除元素
删除元素,就是把各层级中对应的元素删除即可,真的这么简单吗?来让我们上代码:
1 | public V remove(Object key) { |
(1)寻找目标节点之前最近的一个索引对应的数据节点(数据节点都是在最底层的链表上);
(2)从这个数据节点开始往后遍历,直到找到目标节点的位置;
(3)如果这个位置没有元素,直接返回null,表示没有要删除的元素;
(4)如果这个位置有元素,先通过n.casValue(v, null)原子更新把其value设置为null;
(5)通过n.appendMarker(f)在当前元素后面添加一个marker元素标记当前元素是要删除的元素;
(6)通过b.casNext(n, f)尝试删除元素;
(7)如果上面两步中的任意一步失败了都通过findNode(key)中的n.helpDelete(b, f)再去不断尝试删除;
(8)如果上面两步都成功了,再通过findPredecessor(key, cmp)中的q.unlink(r)删除索引节点;
(9)如果head的right指针指向了null,则跳表高度降级;
删除元素举例
假如初始跳表如下图所示,我们要删除9这个元素。

(1)找到9这个数据节点;
(2)把9这个节点的value值设置为null;
(3)在9后面添加一个marker节点,标记9已经删除了;
(4)让8指向12;
(5)把索引节点与它前一个索引的right断开联系;
(6)跳表高度降级;

至于,为什么要有(2)(3)(4)这么多步骤呢,因为多线程下如果直接让8指向12,可以其它线程先一步在9和12间插入了一个元素10呢,这时候就不对了。
所以这里搞了三步来保证多线程下操作的正确性。
如果第(2)步失败了,则直接重试;
如果第(3)或(4)步失败了,因为第(2)步是成功的,则通过helpDelete()不断重试去删除;
其实helpDelete()里面也是不断地重试(3)和(4);
只有这三步都正确完成了,才能说明这个元素彻底被删除了。
这一块结合上面图中的红绿蓝色好好理解一下,一定要想在并发环境中会怎么样。
查找元素
经过上面的插入和删除,查找元素就比较简单了,直接上代码:
1 | public V get(Object key) { |
(1)寻找目标节点之前最近的一个索引对应的数据节点(数据节点都是在最底层的链表上);
(2)从这个数据节点开始往后遍历,直到找到目标节点的位置;
(3)如果这个位置没有元素,直接返回null,表示没有找到元素;
(4)如果这个位置有元素,返回元素的value值;
查找元素举例
假如有如下图所示这个跳表,我们要查找9这个元素,它走过的路径是怎样的呢?可能跟你相像的不一样。。
(1)寻找目标节点之前最近的一个索引对应的数据节点,这里就是5;
(2)从5开始往后遍历,经过8,到9;
(3)找到了返回;
整个路径如下图所示:

是不是很操蛋?
为啥不从9的索引直接过来呢?
从我实际打断点调试来看确实是按照上图的路径来走的。
我猜测可能是因为findPredecessor()这个方法是插入、删除、查找元素多个方法共用的,在单链表中插入和删除元素是需要记录前一个元素的,而查找并不需要,这里为了兼容三者使得编码相对简单一点,所以就使用了同样的逻辑,而没有单独对查找元素进行优化。